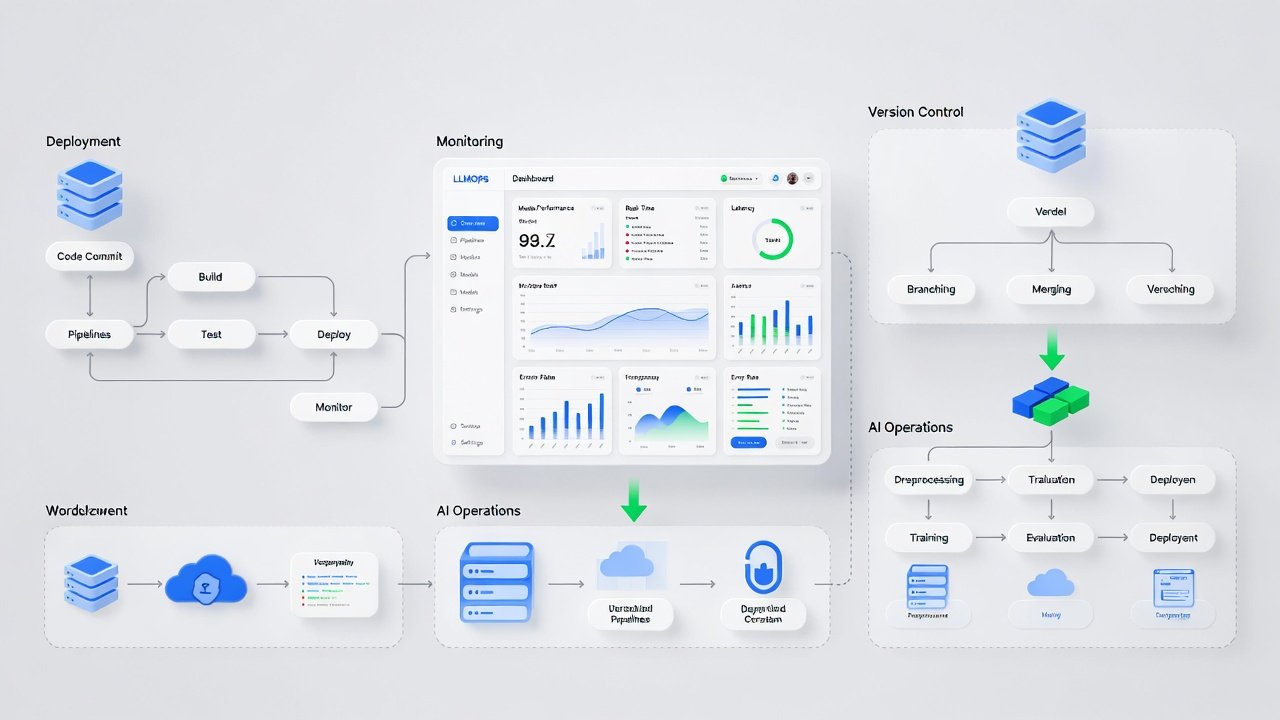
What is Professional AI Operations?
Professional AI Operations (LLMOps) manages the lifecycle of your AI models. It automates deployment and scaling to ensure your AI remains reliable, secure, and cost-effective as your business grows.
At NexGenTech, we build automated quality checks and deployment pipelines. This ensures your AI delivers consistent performance and a clear return on investment every day.
The Business Challenge
Manual updates cause downtime and models lose accuracy over time. Cloud costs often spiral out of control without professional automation and constant monitoring for your team.
Our AI Solution
We design intelligent operations that keep your AI running at peak performance. You get total stability and predictable costs, allowing you to scale without the technical headaches.
High
Reliability